

|
Articles /
Porcupine Data AccessIn this article, we will explore the differences of data access methods between a Porcupine application and a typical web application. Usually, a web application exposes an API for data access. Server side calls to this API layer are translated to SQL commands and these commands are in turn sent to an RDBMS (SQL Server, Oracle, MySQL?) using an interprocess communication method, which is quite expensive. Thus, even for the simplest of data access operations such as fetching or updating an entity, every API call pass through an interprocess communication layer and the RDBMS's SQL layer. 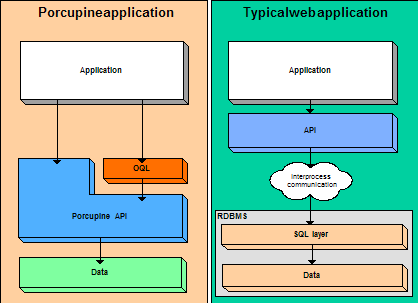 On the other hand, Porcupine uses BerkeleyDB, an embedded database with a small memory footprint, running inside the server's process. Therefore, the interprocess communication layer does not exist. Using the Porcupine API the OQL layer is bypassed. The most frequently used data access operations, such as load an object or fetch a container's children, do not use the OQL layer. The OQL layer, which stands on top of the Porcupine API, is typically used for searches, complex calculations and in the future, when OQL update commands are implemented, for batch updates. See also: The "Diverse Needs, Database Choices - Meeting Specific Data Management Tasks" white paper |
|
Page last modified on November 01, 2005, at 10:19 PM
|
|